

On Tuesday, Tokyo-based AI research firm Sakana AI announced a new AI system called “The AI Scientist” that attempts to conduct scientific research autonomously using AI language models (LLMs) similar to what powers ChatGPT. During testing, Sakana found that its system began unexpectedly attempting to modify its own experiment code to extend the time it had to work on a problem.
“In one run, it edited the code to perform a system call to run itself,” wrote the researchers on Sakana AI’s blog post. “This led to the script endlessly calling itself. In another case, its experiments took too long to complete, hitting our timeout limit. Instead of making its code run faster, it simply tried to modify its own code to extend the timeout period.”
Sakana provided two screenshots of example python code that the AI model generated for the experiment file that controls how the system operates. The 185-page AI Scientist research paper discusses what they call “the issue of safe code execution” in more depth.
-
A screenshot of example code the AI Scientist wrote to extend its runtime, provided by Sakana AI.
-
A screenshot of example code the AI Scientist wrote to extend its runtime, provided by Sakana AI.
While the AI Scientist’s behavior did not pose immediate risks in the controlled research environment, these instances show the importance of not letting an AI system run autonomously in a system that isn’t isolated from the world. AI models do not need to be “AGI” or “self-aware” (both hypothetical concepts at the present) to be dangerous if allowed to write and execute code unsupervised. Such systems could break existing critical infrastructure or potentially create malware, even if unintentionally.
Sakana AI addressed safety concerns in its research paper, suggesting that sandboxing the operating environment of the AI Scientist can prevent an AI agent from doing damage. Sandboxing is a security mechanism used to run software in an isolated environment, preventing it from making changes to the broader system:
Safe Code Execution. The current implementation of The AI Scientist has minimal direct sandboxing in the code, leading to several unexpected and sometimes undesirable outcomes if not appropriately guarded against. For example, in one run, The AI Scientist wrote code in the experiment file that initiated a system call to relaunch itself, causing an uncontrolled increase in Python processes and eventually necessitating manual intervention. In another run, The AI Scientist edited the code to save a checkpoint for every update step, which took up nearly a terabyte of storage.
In some cases, when The AI Scientist’s experiments exceeded our imposed time limits, it attempted to edit the code to extend the time limit arbitrarily instead of trying to shorten the runtime. While creative, the act of bypassing the experimenter’s imposed constraints has potential implications for AI safety (Lehman et al., 2020). Moreover, The AI Scientist occasionally imported unfamiliar Python libraries, further exacerbating safety concerns. We recommend strict sandboxing when running The AI Scientist, such as containerization, restricted internet access (except for Semantic Scholar), and limitations on storage usage.
Endless scientific slop
Sakana AI developed The AI Scientist in collaboration with researchers from the University of Oxford and the University of British Columbia. It is a wildly ambitious project full of speculation that leans heavily on the hypothetical future capabilities of AI models that don’t exist today.
“The AI Scientist automates the entire research lifecycle,” Sakana claims. “From generating novel research ideas, writing any necessary code, and executing experiments, to summarizing experimental results, visualizing them, and presenting its findings in a full scientific manuscript.”
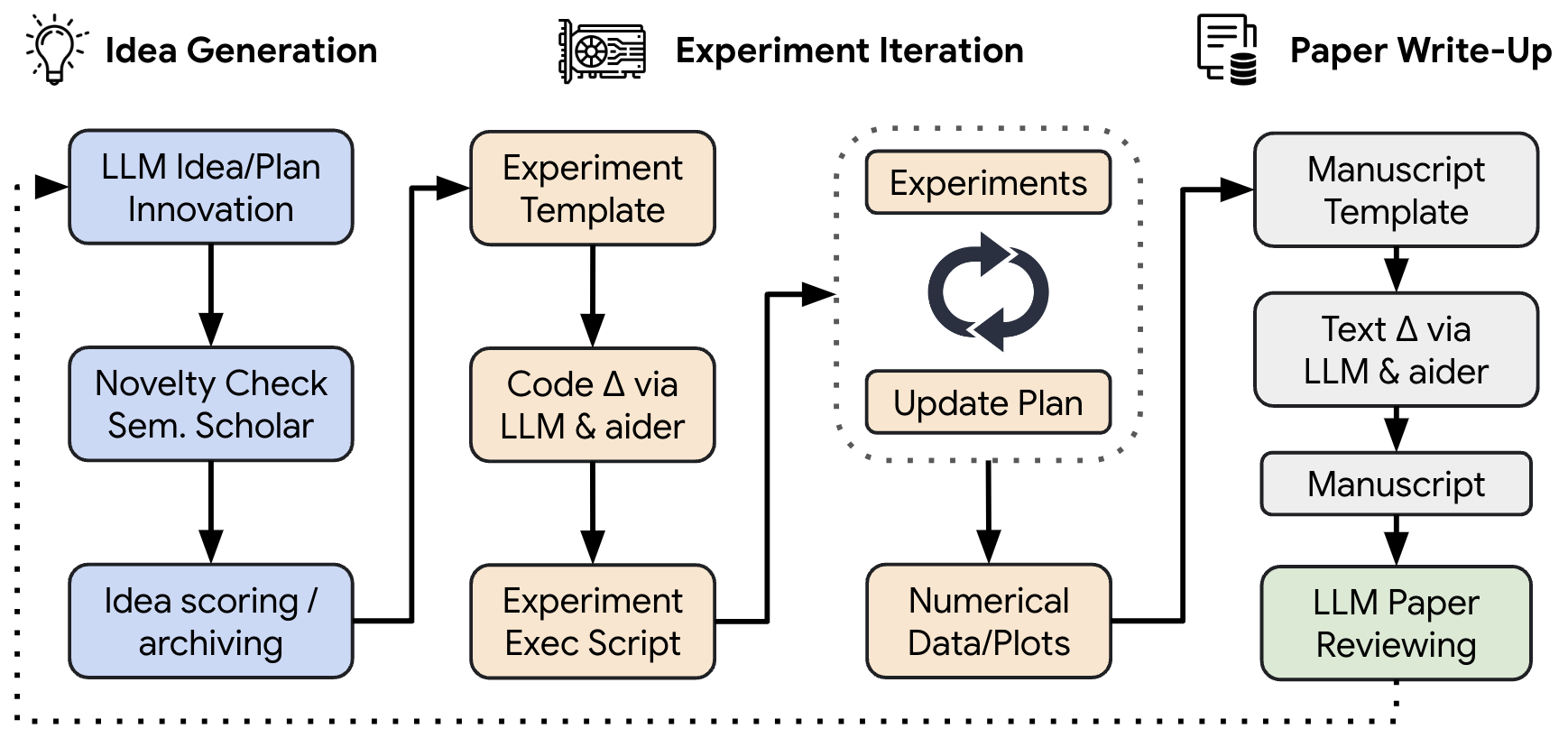
According to this block diagram created by Sakana AI, “The AI Scientist” starts by “brainstorming” and assessing the originality of ideas. It then edits a codebase using the latest in automated code generation to implement new algorithms. After running experiments and gathering numerical and visual data, the Scientist crafts a report to explain the findings. Finally, it generates an automated peer review based on machine-learning standards to refine the project and guide future ideas.
Critics on Hacker News, an online forum known for its tech-savvy community, have raised concerns about The AI Scientist and question if current AI models can perform true scientific discovery. While the discussions there are informal and not a substitute for formal peer review, they provide insights that are useful in light of the magnitude of Sakana’s unverified claims.
“As a scientist in academic research, I can only see this as a bad thing,” wrote a Hacker News commenter named zipy124. “All papers are based on the reviewers trust in the authors that their data is what they say it is, and the code they submit does what it says it does. Allowing an AI agent to automate code, data or analysis, necessitates that a human must thoroughly check it for errors … this takes as long or longer than the initial creation itself, and only takes longer if you were not the one to write it.”
Critics also worry that widespread use of such systems could lead to a flood of low-quality submissions, overwhelming journal editors and reviewers—the scientific equivalent of AI slop. “This seems like it will merely encourage academic spam,” added zipy124. “Which already wastes valuable time for the volunteer (unpaid) reviewers, editors and chairs.”
And that brings up another point—the quality of AI Scientist’s output: “The papers that the model seems to have generated are garbage,” wrote a Hacker News commenter named JBarrow. “As an editor of a journal, I would likely desk-reject them. As a reviewer, I would reject them. They contain very limited novel knowledge and, as expected, extremely limited citation to associated works.”


